import pandas as pd
from pyinaturalist import (
# Observation,
get_observations,
get_taxa_by_id,
get_places_by_id,
# pprint,
)
#import ipyplot
from itertools import islice
import plotly.express as px
#import numpy as np
import geopandas as gpd
from geodatasets import get_path
import matplotlib.pyplot as pltResumen de observaciones de octubre 2024
Python
pyinaturalist
Colombia
México
plotly
El objetivo de esta contribución es resumir la información de mis observaciones en iNaturalist realizadas durante el mes de Octubre de 2024.
En este mes visité hice una salida de campo hacia los Páramos en Boyacá y Cundinamarca, y participé en una reunión de trabajo en Santa Marta. Después de eso tomé unos días de vacaciones para visitar amigos en Barranquilla y Bogotá y a mi familia en Monterrey, México. Durante todos esos viajes realicé observaciones de fauna y flora, y aquí compilo un resumen de las que he añadido a iNaturalist.
Cargar módulos en Python
Primero voy a importar los modules de Python necesarios para descargar la información de iNaturalist (pyinaturalist), algunas herramientas útiles para manipulación de los datos (pandas, numpy, itertools) y otras para visualización (ipyplot, plotly).
Descargar observaciones de iNaturalist
Uso la función get_observations con mi user_id y un intervalo de fechas definido con d1 and d2 para cubrir todo el mes de Octubre de 2024.
username='NeoMapas'
observations = get_observations(user_id=username,
d1="2024-10-01",
d2="2024-10-31",
per_page=0)
n_obs = observations['total_results']print("user {} has {} observations for the selected range of dates".format(username,n_obs))user NeoMapas has 254 observations for the selected range of datesHasta la fecha he subido una pequeña cantidad de observaciones de este mes, pero estoy revisando los archivos viejos para aumentar este número a medida que reviso y clasifico mis archivos de fotos.
En este loop extraigo información específica de cada observación descaragada de iNat. En el registro principal incluyo los datos de la fecha, localidad y especie, pero además extraigo una lista de identificadores que reflejan la jerarquía taxonómica (ident_taxon_ids) y la información geográfica (place_id).
records=list()
places=list()
taxa=list()
j=1
while len(records) < n_obs:
print("Requesting observations from user _{}_: page {}, total of {} observations downloaded".format(username,j,min(j*200,n_obs)))
observations = get_observations(user_id='neomapas',
d1="2024-10-01",
d2="2024-10-31",
per_page=1000,page=j)
for obs in observations['results']:
main_record = {
'uuid': obs['uuid'],
'week': obs['observed_on_details']['week'],
'day': obs['observed_on_details']['day'],
'hour': obs['observed_on_details']['hour'],
'location': obs['place_guess'],
'species guess': obs['species_guess'],
'lat': obs['location'][0],
'long': obs['location'][1]
}
records.append(main_record)
for pid in obs['place_ids']:
place_record = {
'uuid': obs['uuid'],
'place id': pid
}
places.append(place_record)
for tid in obs['ident_taxon_ids']:
taxon_record = {
'uuid': obs['uuid'],
'taxon id': tid
}
taxa.append(taxon_record)
j=j+1Requesting observations from user _NeoMapas_: page 1, total of 200 observations downloaded
Requesting observations from user _NeoMapas_: page 2, total of 254 observations downloadedUso la función de DataFrame de pandas para transformar estas listas en marcos de datos que se me hacen más fáciles para filtrar y manipular más adelante.
inat_obs=pd.DataFrame(records)
places = pd.DataFrame(places)
taxa = pd.DataFrame(taxa)Consultar información taxonómica y geográfica
Voy a utilizar los ids de taxones y lugares para consultar la información más detallada disponible en el API de iNat.
El número de id que quiero consultar excede el número permitido por la función de get_taxa_by_id, así que tengo que dividir la lista en partes:
all_taxa=list(set(taxa['taxon id']))
def chunk(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())Por tanto tengo que hacer un loop dentro de un loop para consultar todos los ids relevantes y extraer la información de los diferentes niveles jerárquicos (rank).
for slc in chunk(all_taxa,30):
taxa_query = get_taxa_by_id(slc, rank_level=[70,60,50,40,30,20,10])
for res in taxa_query['results']:
qry = taxa.loc[taxa['taxon id'] == res['id'],'uuid']
inat_obs.loc[inat_obs.uuid.isin(qry), res['rank']] = res['name']Según el API reference:
Some example values for
rank_levelare 70 (kingdom), 60 (phylum), 50 (class), 40 (order), 30 (family), 20 (genus), 10 (species), 5 (subspecies)
En el caso de los ids de localidades, podemos incluirlos todos en una misma consulta, pero tenemos que hacer la asignación del nivel más explícita:
all_places=list(set(places['place id']))
response = get_places_by_id(all_places,
admin_level=[0, 10])
for res in response['results']:
qry = places.loc[places['place id'] == res['id'],'uuid']
if res['admin_level'] == 0:
level='country'
elif res['admin_level'] == 10:
level='state'
inat_obs.loc[inat_obs.uuid.isin(qry), level] = res['name']Según el API reference: > Admin level of a place, or an array of admin levels in comma-delimited format. Supported admin levels are: -10 (continent), 0 (country), 10 (state), 20 (county), 30 (town), 100 (park)
Resumir datos por fecha y localidad
Para resumir las observaciones quiero agrupar y agregar los datos, y puedo hacer esto con las funciones de pandas, por ejemplo:
agg_funcs = {'uuid':['count']}
group_columns = ['country','state','day']
inat_obs.groupby(group_columns).agg(agg_funcs)| uuid | |||
|---|---|---|---|
| count | |||
| country | state | day | |
| Colombia | Atlántico | 16 | 1 |
| Boyacá | 5 | 14 | |
| 6 | 2 | ||
| 7 | 3 | ||
| Cundinamarca | 3 | 13 | |
| 4 | 53 | ||
| 24 | 10 | ||
| 26 | 1 | ||
| Magdalena | 11 | 6 | |
| 13 | 8 | ||
| 14 | 5 | ||
| Mexico | Nuevo León | 20 | 130 |
| 21 | 8 |
gdf=gpd.GeoDataFrame(
inat_obs,
geometry=gpd.points_from_xy(inat_obs.long, inat_obs.lat),
crs=4326
)world = gpd.read_file(get_path("naturalearth.land"))# We restrict to South Australia.
ax = world.clip([-120, 0, -70, 30]).plot(color="white", edgecolor="black")
# We can now plot our ``GeoDataFrame``.
gdf.plot(ax=ax, color="red")
plt.show()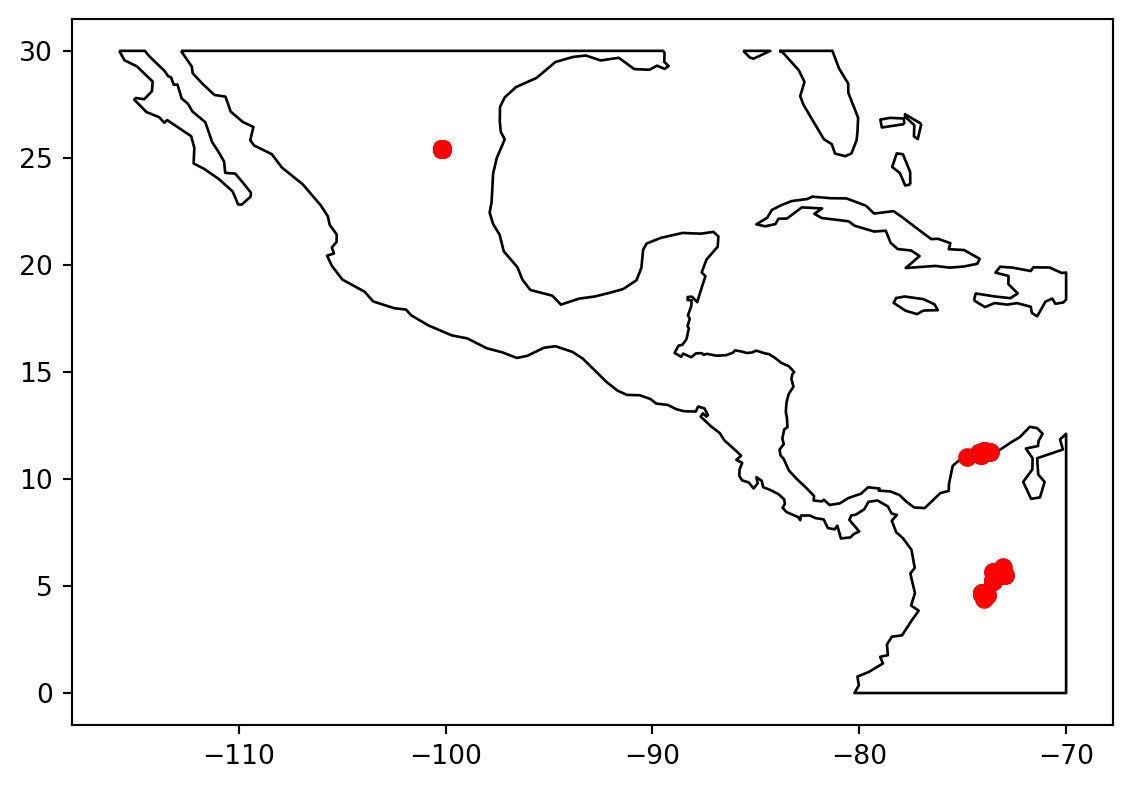
Resumir información de grupos taxonómicos
Para resumir la información taxonómica voy a utilizar los gráficos interactivos que ofrecen una oportunidad para explorar y controlar el nivel de detalle que más le interese. Vamos a intentar aquí usar la función treemap del paquete plotly.
Voy a reutilizar una función que diseñe en una de mis contribuciones previas, y que me permite agrupar los datos y crear la figura:
def group_and_plot_data(x,aggfuncs,groupcols):
gd=x.groupby(groupcols).agg(aggfuncs).reset_index()
gd.columns = [' '.join(col).strip() for col in gd.columns.values]
value_col = gd.columns.values[-1]
fig = px.treemap(gd,
path=[px.Constant("Obs from Oct 2024"),] + groupcols,
values=value_col,
color=value_col,
hover_data=[value_col],
color_continuous_scale='RdBu')
fig.update_layout(margin = dict(t=5, l=5, r=5, b=5))
return(fig)Y de esta forma podemos mostrar los resultados considerando los niveles taxonómicos que queramos:
group_columns = ['kingdom','phylum','class','order','family']
fig1 = group_and_plot_data(inat_obs, agg_funcs, group_columns)
fig1.show()Conclusión
Este es un ejemplo sencillo que me permite resumir la información de las observaciones de este mes. En este caso estoy reutilizando fragmentos de códigos que he generado anteriormente.