
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point
from datetime import datetime
from pyinaturalist import get_observations
import ipyplot
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import CounterMis fotos del año 2009
Python
pyinaturalist
seaborn
wordcloud
Español
Venezuela
Italia
Papilionoidea
En el año 2009 continuamos con proyecto sobre la relación entre la mariposa Kricogonia lyside y el Guayacán (Guaiacum officinale) y nos preparamos para otra temporada de muestreo del proyecto NeoMapas. Un año muy interesante con varias salidas de campo por diferentes regiones de Venezuela.
Para poner estas observaciones de 2009 en contexto temporal de mis contribuciones a iNat, pueden revisar este gráfico
Después de terminar de actualizar mis observaciones de 2008, 2010 y otros años, he decidido repetir el proceso para el año 2009. Este documento me permite visualizar las fotos que ya están en iNaturalist y así evitar subir fotos por duplicado.
Lamentablemente solo tomamos unas pocas fotos en algunos de los viajes de este año, y entre ellas no he encontrado muchas fotos para contribuir en iNaturalist.
Cargar módulos en Python
Importamos los módulos necesarios:
Y declaramos una función útil para leer los datos temporales de la respuesta del API de iNat:
def as_date(x):
if type(x) == str:
y = datetime.strptime(x, "%Y-%m-%d").date()
else:
y = datetime.date(x)
return(y)Descargar datos
Los datos espaciales de los estados de Venezuela están disponibles a través de esta página del Humanitarian Data Exchange: https://data.humdata.org/dataset/cod-ab-ven Usamos read_file del modulo geopandas para abrir esta capa desde el url de descarga.
zipurl = 'https://data.humdata.org/dataset/5b141d29-534f-4f01-a0bc-41e2f375d925/resource/b6cf4bf5-418a-49ad-80ec-b84d0e0e0d41/download/ven_adm_ine_20210223_shp.zip'
vzla_estados=gpd.read_file(zipurl,
layer='ven_admbnda_adm1_ine_20210223',
columns=['ADM1_ES','geometry'])Usamos get_observations con un intervalo de fechas que incluye todo el año 2010:
observations = get_observations(user_id='NeoMapas',
d1="2009-01-01",
d2="2009-12-31",
per_page=1000)Este número aumenta a medida que cargamos observaciones en iNat:
len(observations['results'])69
Usamos este loop para guardar la información básica de cada observación:
records=list()
for obs in observations['results']:
record = {
'uri':obs['uri'],
'species guess': obs['species_guess'],
'location': obs['place_guess'],
'longitude': obs['location'][1],
'latitude': obs['location'][0],
'Fecha_obs': as_date(obs['observed_on']),
'Fecha_reg': as_date(obs['created_at']),
'tags': obs['tags']
}
if len(obs['observation_photos'])>0:
record['url'] = obs['observation_photos'][0]['photo']['url'].replace("square","medium")
record['attribution'] = obs['observation_photos'][0]['photo']['attribution']
records.append(record)Y las transformamos en un marco de datos con información espacial para usar con geopandas:
gs = [Point(float(obs['longitude']), float(obs['latitude'])) for obs in records]
inat_obs=gpd.GeoDataFrame(records, geometry=gs, crs="EPSG:4326")Añadimos una columna con el mes de la observación:
inat_obs['mes'] = [fobs.month for fobs in inat_obs['Fecha_obs']]Resumen de las observaciones por estado
Primero combinamos la información de iNat con los estados de Venezuela. Usamos la función sjoin_nearest porque algunas observaciones provienen de la costa y las coordenadas de especies amenazadas están protegidas.
crs_lacanoa="EPSG:24719"inat_obs_estados = gpd.sjoin_nearest(
inat_obs.to_crs(crs_lacanoa),
vzla_estados.to_crs(crs_lacanoa),
distance_col="distances",
how="left",
max_distance=50000,
lsuffix='in',
rsuffix='vzla')inat_obs_estados.fillna({'ADM1_ES':'No info'},inplace=True)Hacemos una tabla de contingencia usando el estado y el mes de observación:
data_crosstab = pd.crosstab(inat_obs_estados['ADM1_ES'],
inat_obs_estados['mes'],
margins = True)Y mostramos esta información gráficamente usando una de las funciones del paquete seaborn:
plt.figure(figsize=(8, 6))
sns.heatmap(data_crosstab, annot=True, fmt='d', cmap='YlGnBu', linewidths=.5)
plt.title('Observaciones por estado')
plt.ylabel('Estados')
plt.xlabel('Mes del año')
plt.tight_layout()
plt.show()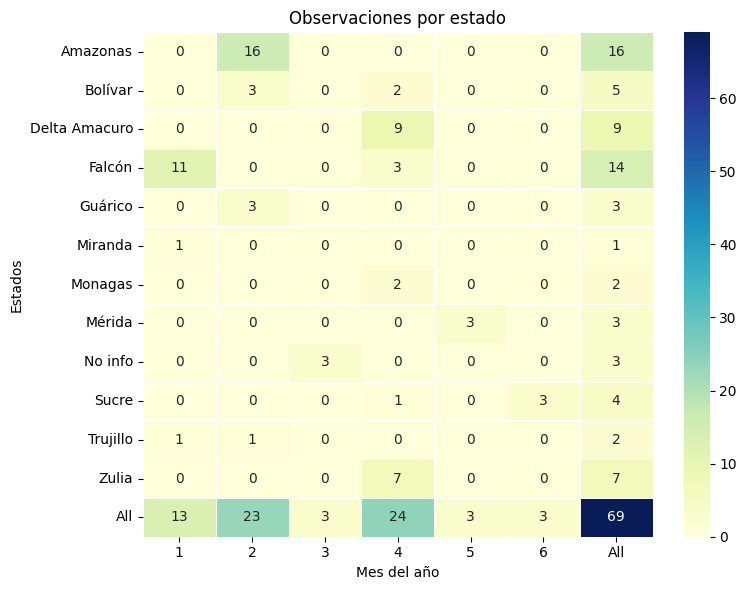
Observaciones etiquetadas
Algunas observaciones cuentan con etiquetas o tags:
inat_obs['ntags'] = [len(x) for x in inat_obs.tags]
inat_obs.groupby('ntags').agg({'uri':'count'})| uri | |
|---|---|
| ntags | |
| 0 | 15 |
| 1 | 49 |
| 2 | 3 |
| 3 | 1 |
| 6 | 1 |
Podemos calcular la frecuencia de cada etiquetas usando la función Counter:
taglist=list()
for x in inat_obs.tags:
taglist = taglist + x
tagcounts=Counter(taglist)tagcountsCounter({ 'Muestreos de NeoMapas': 53, 'NM02': 1, 'NM27': 1, 'NM09': 1, 'endemic butterflies': 1, 'NeoMapas': 1, 'Mariposas de Venezuela': 1, 'parques nacionales': 1, 'Mamíferos': 1, 'Cordillera de Mérida': 1, 'Laguna de Mucubají': 1, 'páramos': 1 })
Y visualizar estas frecuencias con una nube de palabras (WordCloud):
wordcloud = WordCloud(colormap='plasma', width = 1000, height = 150).generate_from_frequencies(tagcounts)
plt.figure(figsize=(15,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
Progreso
Aquí se puede ver el progreso que he hecho en cargar las fotos del año 2008, creo que estas son todas las que tengo respaldadas:
aggfuns = {
'Fecha_obs': ["min", "max"],
'location': ['count',pd.Series.nunique],
'species guess': [pd.Series.nunique],
}
inat_obs.groupby('Fecha_reg').agg(aggfuns)| Fecha_obs | location | species guess | |||
|---|---|---|---|---|---|
| min | max | count | nunique | nunique | |
| Fecha_reg | |||||
| 2015-06-14 | 2009-05-16 | 2009-05-16 | 1 | 1 | 1 |
| 2020-09-19 | 2009-05-16 | 2009-05-16 | 1 | 1 | 1 |
| 2021-05-24 | 2009-06-10 | 2009-06-10 | 1 | 1 | 1 |
| 2021-06-01 | 2009-01-23 | 2009-06-13 | 10 | 3 | 10 |
| 2023-11-18 | 2009-05-16 | 2009-05-16 | 1 | 1 | 1 |
| 2024-11-16 | 2009-03-12 | 2009-03-12 | 3 | 2 | 3 |
| 2025-03-21 | 2009-04-08 | 2009-04-22 | 16 | 7 | 15 |
| 2025-03-22 | 2009-02-19 | 2009-04-24 | 26 | 10 | 23 |
| 2025-08-14 | 2009-01-26 | 2009-01-26 | 2 | 1 | 2 |
| 2025-08-31 | 2009-01-17 | 2009-02-22 | 8 | 7 | 8 |
Todas las observaciones
Y cierro aquí con todas las imágenes de las observaciones de este año:
Enero
Con estas líneas de código podemos filtrar por fecha de observación:
ss = inat_obs['mes'] == 1
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)












Febrero
ss = inat_obs['mes'] == 2
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)






















Marzo
En Marzo estuve participando en un curso en Trieste, Italia, y tengo un par de observaciones:
ss = inat_obs['mes'] == 3
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)


Abril
ss = inat_obs['mes'] == 4
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)






















Mayo
ss = inat_obs['mes'] == 5
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)


Junio
ss = inat_obs['mes'] == 6
images = inat_obs.loc[ss,'url']
labels = inat_obs.loc[ss,'species guess']
ipyplot.plot_images(list(images), list(labels), max_images=60,)

